
Hunspell
Qu’est ce que c’est ?
Vous avez peut-être déjà entendu parler de hunspell, un système de vérification orthographique utilisé par des logiciels tel que OpenOffice, LibreOffice ou certains produits de Mozilla pour ne pas tous les citer. Il s’agit souvent d’une fonctionnalité intégrée au logiciel même, permettant aux utilisateurs d’installer suivant leur besoin les dictionnaires de leur choix pour que les mots qu’ils écrivent puissent être vérifié en direct. Peu connu du grand publique Hunspell est pratique pour les projets informatiques car les données sont facilement modifiables et toute personne peut apporter sa contribution en ajoutant des mots à son dictionnaire en local et peut même le partager.
Format des données
Pour être plus précis le dictionnaire est composé de 2 fichiers :
- Un fichier avec une extension « .dict » qui contient une liste de tous les mots avec quelques informations supplémentaires comme le type (nom ou verbe, …), le genre (masculin, féminin, …) à l’exception de sa définition
- Un fichier avec une extension « .aff » qui contient principalement des règles spécifiques comme la déclinaison des pluriels, etc…
Les données sont sauvegardées dans un format texte brut, sans compression, donc même si le fichier « dict » peut être grand en taille, il est possible de l’ouvrir avec un éditeur de texte classique tel que Kate ou Notepad++ ! Pas mal non ?
That’s all folks
Tout cela sonne bien, mais c’est plus compliqué pour les développeurs comme moi qui travaille avec les navigateurs – le logiciel que vous utilisez pour afficher vos pages internet telles que Mozilla Firefox, Google Chrome, ou Microsoft Edge. Même si la fonctionnalité est parfois intégrée et prête à l’emploi, et même si des dictionnaires sont déjà disponibles sous différents formats dans votre système d’exploitation – l’environnement dans lequel vous utilisez vos logiciels comme Linux, Apple MacOS et Microsoft Windows, le programme exécuté dans le navigateur qui permet de vérifier l’orthographe à la volée – aussi connu comme WYSIWYG – n’a pas accès à ces données. Ou du moins pas d’une manière simple et surtout universel.
Cela peut ne pas sembler logique pour un utilisateur du logiciel, mais cela l’est. Parler tout seul n’est pas pareil que parler à son voisin, d’un point de vue communication. Les systèmes de gestion de contenu sont des lignes de code s’exécutant dans votre navigateur – en local – mais peut utiliser des composants et données de locations à distance comme un serveur. Dès que le réseau est impliqué, les permissions ne sont pas gérées de la même manière, etc…
Glissement sémantique
Dès que l’on gère plusieurs langues ou plusieurs fuseaux horaires par exemple, il y a toujours plusieurs manières d’aborder le problème et de construire une solution. Je commence toujours par regarder ce qu’il existe d’existants.
La version gratuite/légère de l’extension Markup Markdown est basée sur EasyMDE, un éditeur dont le code source est libre, et utilise CodeMirror comme moteur. Pour donner une image CodeMirror est pour EasyMDE ce qu’est le moteur dans votre voiture ou moto.
Sur Github, il y a plusieurs mises à jour disponibles abordant la problématique, par exemple :
- https://github.com/Ionaru/easy-markdown-editor/issues/78
- https://github.com/Ionaru/easy-markdown-editor/pull/333
Ce fut bien surprenant et d’une grande utilité, mais cela ne correspond pas complètement à ce que je recherche, car charger un dictionnaire dans une langue différente est un processus qui se nomme :
Internationalisation
Nom du processus pour rendre un logiciel disponible dans une autre langue, un parmi plusieurs des métiers de la branche des traductions. Vous ajoutez une couche de données supplémentaires et des fonctionnalités complémentaires si besoin comme par exemple écrire de droite à gauche pour que les personnes parlant une autre langue puissent profiter pleinement des possibilités de votre logiciel. Et différentes langues ne signifient pas forcément différents pays. Par exemple en Suisse, certaines personnes parlent allemand, français ou encore italien. Et à l’intérieur d’un même pays, il peut aussi y avoir des langues locales telles que le Breton en France, donc… Cela devient un travail de grande envergure !
L’anglais étant la langue internationale par défaut, à moins que le logiciel ne soit conçu pour un pays spécifique, on commence souvent avec la langue anglaise par défaut et ensuite dans un second temps, on publie des paquets linguistiques contenant la traduction des interfaces et autres éléments. Par exemple, j’ai longtemps utilisé MacOS avec les langues asiatiques (japonais, chinois, coréen) ou encore la version française de Word dans Microsoft Windows version américaine. Principalement, vous utilisez une seule langue à la fois, comme si par exemple bien que votre langue maternelle soit le français, vous utilisiez un dictionnaire anglais pour vérifier en anglais un mot dont vous ne connaissez pas l’écriture.
Multi-langues
Ou tout dérivé de ce mot est la possibilité de travailler avec différentes langues dans un même environnement. On donne la possibilité à l’utilisateur d’utiliser plusieurs langues au sein d’un même logiciel. Cela n’est pas plus complexe mais loin d’être simple. Par rapport aux fonctionnalités qu’on essaie de créer, cela peut être utilisé plusieurs langues en même temps – par exemple la vérification orthographique d’une citation russe dans un texte en français, ou dans des espaces différents comme par exemple éditer en même temps la même version d’un document dans deux langues dans deux fenêtres séparées. Côté programmation cela devient beaucoup plus intense !
En supplément des paquets linguistiques au niveau du système d’opération, on pousse à un niveau plus avancé, comme l’installation de Microsoft IME qui vous permet d’écrire des caractères asiatiques à l’aide du clavier. Pour vous permettre d’écrire – et pas seulement d’afficher – une citation d’une autre langue dans votre article de blog, vous avez besoin de fonctionnalités supplémentaires et surtout d’avoir accès aux données de plusieurs langues à la fois. Pour poursuivre l’exemple précédent de l’internationalisation, cette fois-ci c’est comme si vous aviez un dictionnaire bilingue Français-Anglais et que vous cherchiez la définition en français du mot en anglais.
Résumé
La prise en charge linguistique couvre un large éventail de domaines allant de l’internationalisation aux multi-langues. Si l’on se contente des langues basées sur le latin, l’internationalisation va rendre l’interface du système d’exploitation disponible dans une autre langue. Il s’agit souvent d’interagir avec une langue à la fois avec l’ordinateur grâce à des données ou logiciels complémentaires. Je ne dis pas que c’est facile, c’est déjà un énorme travail à fournir. Pousser le concept plus loin avec 2 ou 3 langues en même temps, cela devient beaucoup plus complexe avec les différentes combinaisons possibles et les différentes manières de proposer une même fonctionnalité.
Ma solution
Revenons sur notre éditeur markdown, CodeMirror a déjà une extension de vérification orthographique appelée SpellChecker, par exemple cette bifurcation utilisant Typo.js comme moteur principal qui lit les fichiers Hunspell! C’est un bon point. Comme décrit dans la problématique 37, il y a 2 solutions possible:
- Créér son propre dictionnaire unique (Ajout des mots d’une autre language, d’expressions du langage familier, etc…)
- Charger plusieurs dictionnaires
J’ai décidé d’aller pour la solution 2, charger plusieurs dictionnaires. Mais il y a plusieurs incohérences introduite dans la vérification orthographique, un mot pourrait être identifié dans différentes langues, etc… Donc je suis parti sur une solution hybride:
- Installer un dictionnaire sur votre serveur
- Définir le choix de la langue principale
- Pour terminer lorsque vous écrivez votre contenu vous devez spécifier la portion de texte utilisant une langue différente grâce à un bouton dans la barre d’outils de l’éditeur
1. Installer un ou plusieurs dictionnaires
Depuis le menu Settings -> Markup Markdown, il y a maintenant un onglet appelé Spell Checker (Experimental).
Sélectionnez un dictionnaire puis cliquez sur le bouton “Install”. Commençons par le dictionnaire anglais :

A cet instant les données du dictionnaire devraient être installées et prêtes à l’emploi. Cliquez sur la case à cocher pour le rendre actif et n’oubliez pas de faire défiler la page jusqu’en bas et cliquer sur le bouton Update pour enregistrer vos préférences.

Si tout s’est déroulé correctement, maintenant l’écran de connexion doit ressembler à ceci :
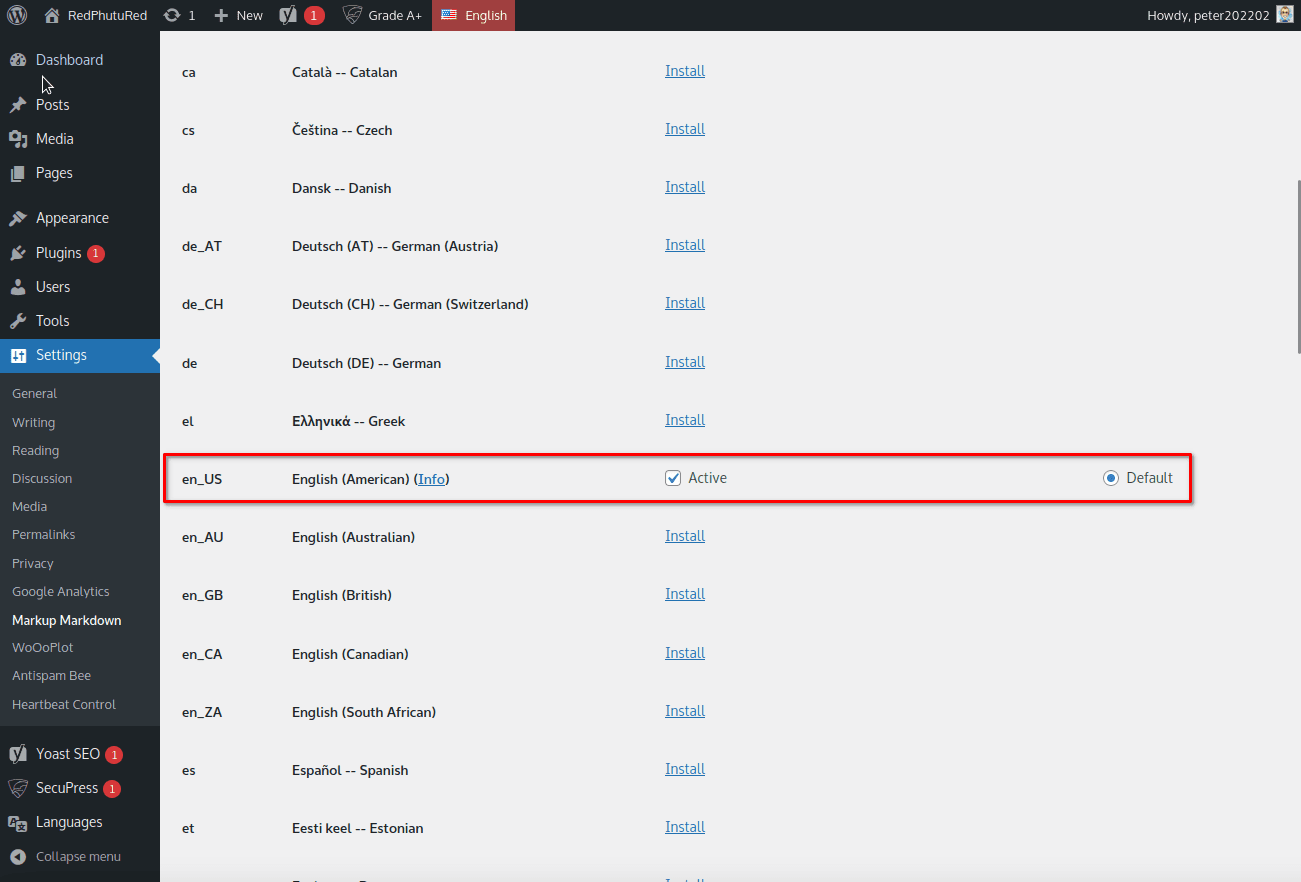
Répétons l’opération avec le dictionnaire français. Maintenant nous avons 2 dictionnaires installées et actifs :
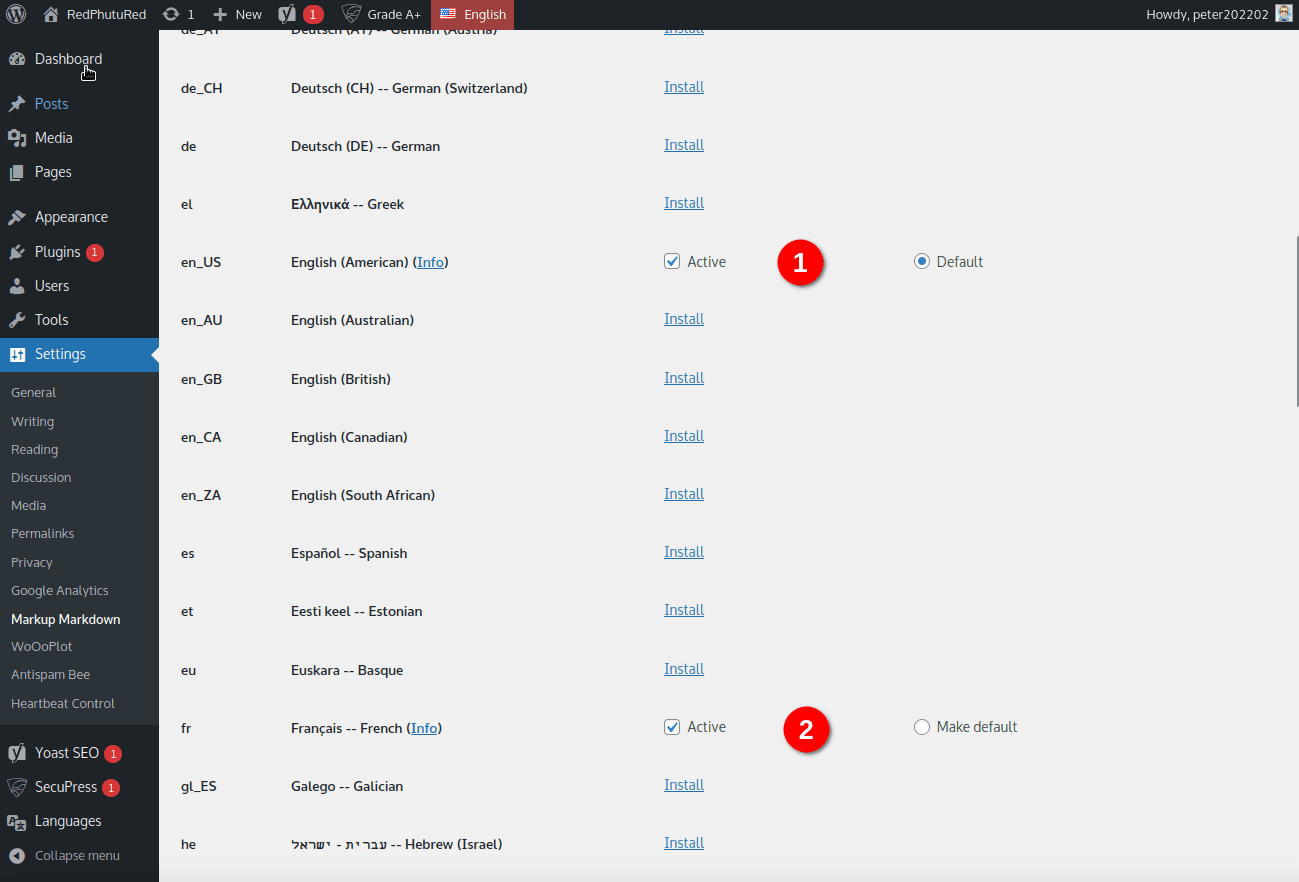
2. Choisir le dictionnaire principal
En examinant l’image précédente, vous pouvez voir qu’il y a une case à cocher avec le statut Active (Actif) ou non. Si vous ne cochez pas la case, les données du dictionnaire sont bien présentes sur votre serveur, mais la vérification orthographique ne sera pas activée. Cela vous permet d’installer différents dictionnaires pour une même langue et de les désactiver ou activer manuellement sur demande.
Maintenant, sur la partie droite, il y a un bouton radio (le bouton rond) qui vous permet de définir le dictionnaire par défaut : ce sera la langue utilisée par défaut pour la vérification orthographique ! Cela signifie que dans la configuration en cours, par ordre d’installation le dictionnaire anglais est celui par défaut et en complément le dictionnaire français sera chargé.
Donc, en éditant le contenu d’un article, l’orthographe de tous les mots sera vérifiée par rapport au dictionnaire anglais par défaut, et ensuite, il faudra étiqueter manuellement les portions de texte écrites en français. À l’inverse, si le dictionnaire français est défini par défaut, l’orthographe sera vérifié par rapport au dictionnaire en français, et ensuite il faudra étiqueter les portions de texte en anglais. (Voir l’étape suivante)
3. Spécifier le contenu avec une langue alternative
Dernière partie ! Pour continuer avec la capture d’écran de l’exemple précédent, si le dictionnaire par défaut sélectionné est l’anglais et qu’un second dictionnaire français est activé, alors dans la barre d’outil de l’éditeur un bouton « FR » (code de la langue française) va s’afficher entre le bouton de titres et le bouton de citation.
L’anglais étant la langue par défaut, tous les mots en français – “Bonjour cher ami” – sont marqués comme erreur lors de la vérification orthographique. Alors fixons cela !
Sélectionnez le texte (couleur grise dans la capture d’écran) et appuyez sur le bouton “FR” :
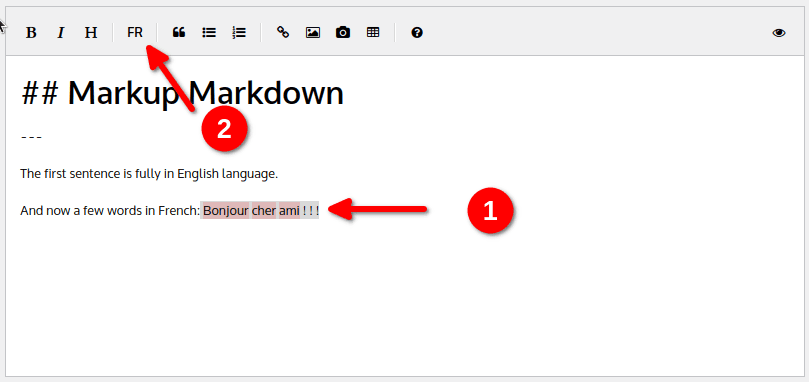
Le texte est maintenant encapsulé dans une balise html span comme ceci :
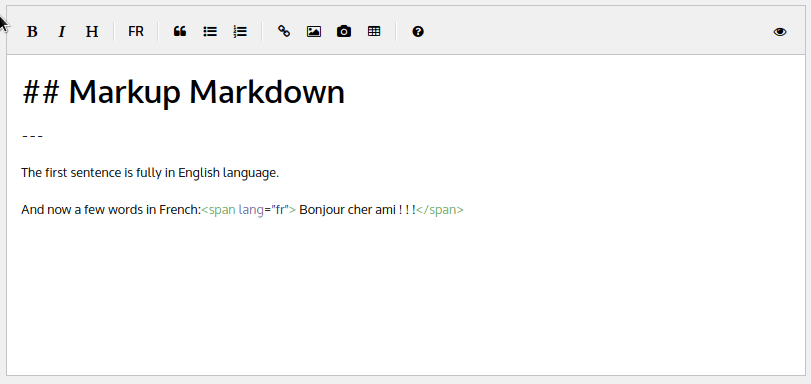
Tout est bon ! Maintenant, si on remplace « Bonjour » par un mot plus familier comme « bijour » et « ami » par un mot anglais comme « friend », dans le contexte de la langue française ces deux mots ne sont pas validés par la correction orthographique automatique :
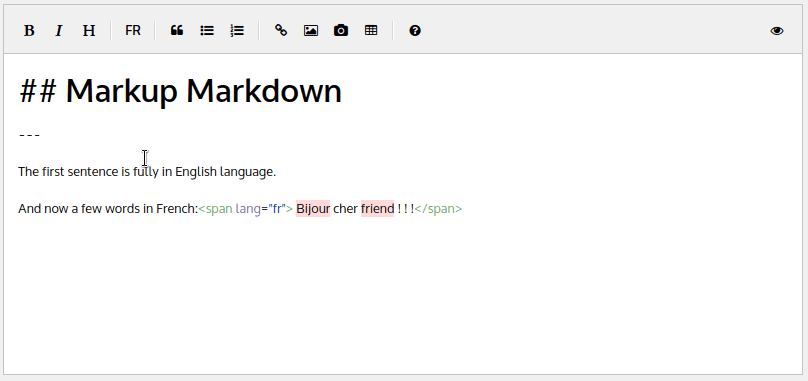
Si vous ne le saviez pas, les bonnes pratiques d’accessibilité dans les recommandations publiées par différents organismes vous suggèreraient déjà d’étiqueter la langue pour l’ensemble du document ou les portions de texte spécifiques, donc une étape manuelle sera bénéfique en terme d’accessibilité et même de SEO ! 😉
Conclusion
N’oubliez pas que les dictionnaires vont être chargés dans la mémoire de votre navigateur. Ces dictionnaires pouvant être volumineux en taille et en poids, suivant la puissance de votre ordinateur, je ne recommande de ne pas en activer plus de 2 à la fois. Plusieurs indications sont inscrites dans l’écran de configuration pour vous guider au maximum.
Il existe d’autres solutions à investiguer comme activer “manuellement” la vérification par défaut du navigateur, mais pour toutes les solutions trouvées, d’après mes recherches étiqueter les différents langues utilisées manuellement est la meilleure solution – pour le moment – pour créer du contenu dans plusieurs langues.
Ce fut un défi d’une fin de semaine réussi avec succès, tout est loin d’être parfait, mais avoir une vérification orthographique multi-lingue dans un navigateur est un exploit pour moi, et j’espère que beaucoup de personnes pourront en bénéficier.